Can AI Predict Horse Races? What a Machine Model Can and Can't Do
A straight answer on machine-learning racing models — what they are genuinely good at, what they cannot see, and why a rating still isn't a betting system.
Short answer: a good model predicts races better than the average punter, and not as well as the hype suggests. The useful version of the question isn't "can AI win?" — it's "what does a model actually know, and where does it go blind?"
What a Racing Model Really Is
A modern racing model gives every horse a probability, and those probabilities add up to 100% across the field. That framing — treat the race as a competition, output odds rather than a single "this one wins" — is the foundation every serious model rests on, and it dates back to academic work in the 1980s, not last year's AI boom.
The most famous proof is Bill Benter, whose Hong Kong syndicate won close to a billion dollars over two decades on a model built exactly this way. Three lessons from that work drive every honest model since:
- Output probabilities, not point predictions.
- Combine with the public. Benter's standalone model was biased relative to the market; his breakthrough was blending his ratings with the public odds. The combined model beat either one alone.
- The edge is small and it erodes. His advantage over the crowd was one to two percentage points — tiny, but enough with discipline. And the accuracy needed to clear the Hong Kong market rose by roughly 40% over twenty years as everyone's numbers sharpened. An edge is never banked. It's defended.
What the Model Is Genuinely Good At
It reads patterns across a volume of races no human can hold in their head. It never has a bad day, never anchors to a horse's reputation, never gets bored in race six. For the baseline question of what we should expect, all else equal, it's excellent. The best models are ensembles: several different models blended, because different models make different mistakes and averaging cancels the errors faster than the signal.
What It Can't See
The model doesn't watch races. It doesn't know the trainer moved yards last week, that the stable jockey was quietly replaced, that a horse was boxed in and never got a run, or that today's three front-runners will burn each other off. Those are your lenses.
It also depends entirely on its inputs. A debutant with no history, or a horse with a thin record on today's surface, gives the model little to work with; treat its number as low-confidence there. And any serious model is built to avoid data leakage: letting it peek at information that didn't exist before the off. A model that leaks looks brilliant in backtests and loses money live. The rule is that at prediction time it can only see what a bettor could have seen five minutes before the gates opened.
Why a Rating Still Isn't a Betting System
Here's the part that separates a straight answer from a sales pitch. Take the highest-rated horse in each race across our full history: it wins about 20%, roughly double an average runner, and it beats the market's own margin-free estimate by about 6% (8% at short prices). The number carries information the price doesn't.
And yet a flat bet on it loses money at every price, because when you actually bet you pay the takeout, 15% to 25%, on every ticket. Beating the crowd's estimate by 6% is not the same as beating a price that has a quarter taken out of it first.
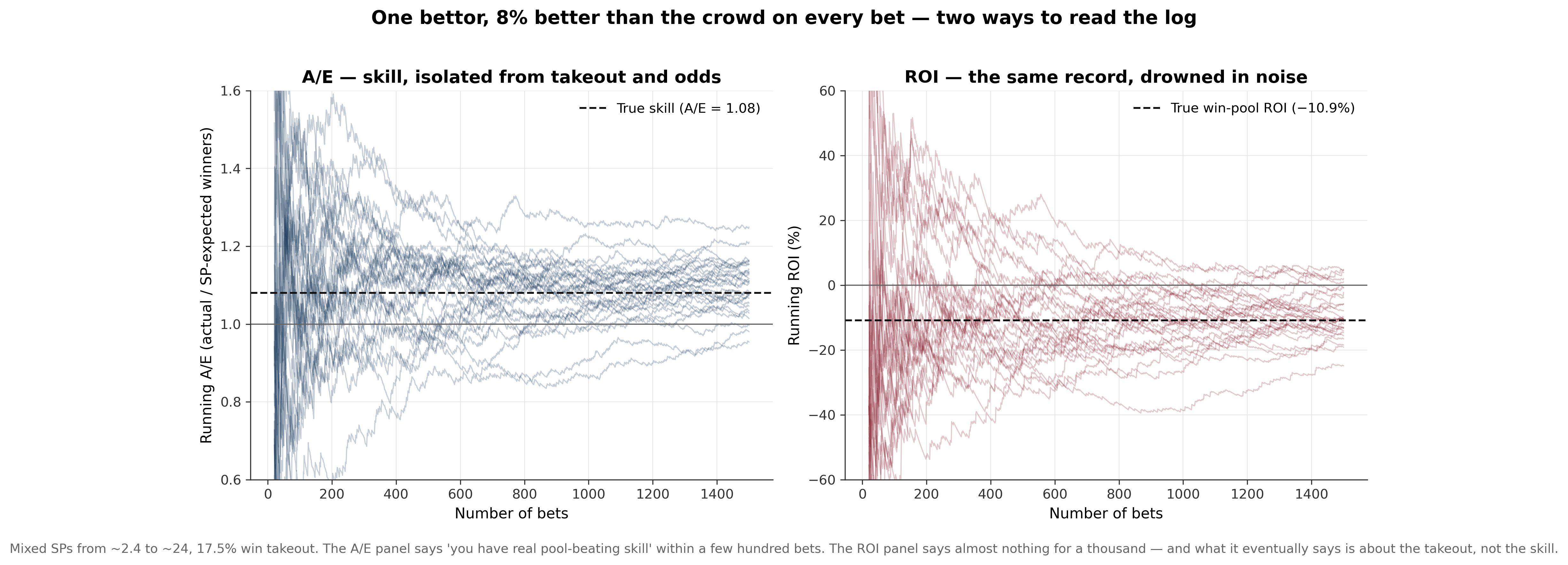
So why does the model matter? Because a single number, with zero judgement applied, claws back most of the takeout and lands you about 6% closer to the truth than the market's own consensus. That's the floor you start from. The rest is how you turn that floor into profit: skipping the races where you have nothing, betting only the overlays, playing the deepest pools.
The model gets you to the line. Your judgement steps you over it. Anyone selling you the model as the whole answer is selling you the line as if it were the finish.
Start from a better baseline. MWP's expected rating is a machine model trained on millions of starts, sitting next to the performance rating on every runner — your starting point, not your answer. Try a real racecard and read the model on each runner, or learn how it is built in Do Your Homework, chapter 11.
Related: Value betting: price over winners · Ratings and speed figures explained